
Blog
将本地 AI 推理作为公共基础设施的理据 (The Case for Local AI Inference as Civic Infrastructure)
针对云端托管 AI API 的日益抵制,正将本地推理 (local inference) 从一种小众偏好提升为基础设施需求。通过优先考虑数据主权 (data sovereignty)、环境责任 (environmental accountability) 与透明模型权重 (transparent model weights),开发者正在构建自托管栈 (self-hosted stacks),将用户自主权 (user autonomy) 视为架构约束,而非事后补救。
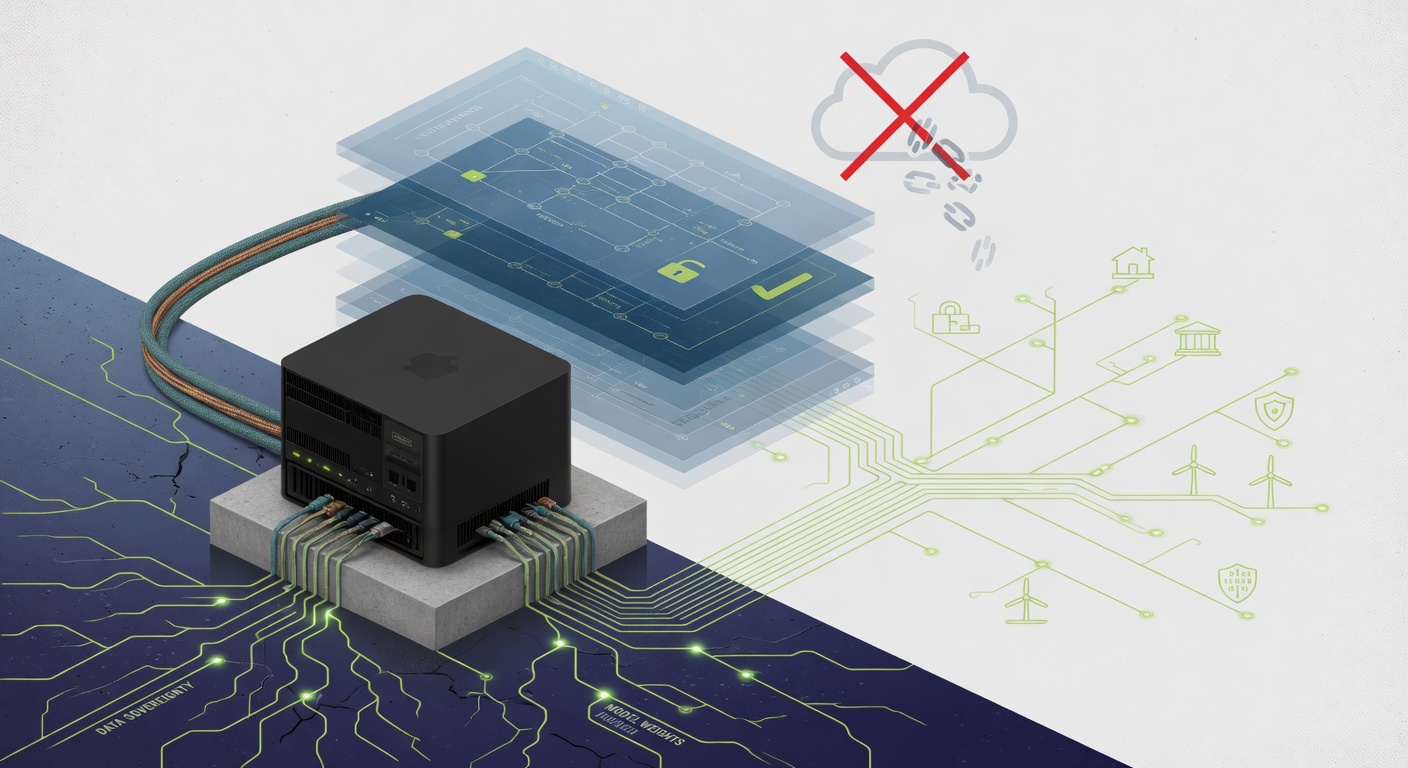
人工智能的架构正在经历一场静默却决断的重构。越来越多的开发者与公共技术从业者 (civic technologists) 正主动拒绝云端托管 API 消费这一默认路径,转而倡导本地执行、开放权重 (open-weight) 的推理架构。这一转变在社区讨论中近期得到凸显,它将去中心化推理 (decentralized inference) 定位为一种结构性必然,而非小众偏好,以捍卫用户自主、经济韧性与环境可持续性。其底层前提清晰而直接:当 AI 从实验性工具转变为公共与个人基础设施时,数据本地化 (data locality) 与执行边界 (execution boundaries) 必须被视为基础要求,而非可选特性。
该范式的技术可行性已迅速成熟。现代本地推理栈 (local inference stacks) 现已能从容适配消费级 GPU、Apple Silicon 与移动 SoC,这得益于精密的量化管线 (quantization pipelines) 与优化的服务运行时 (serving runtimes)。Ollama 与 LM Studio 等项目已标准化了硬件与模型权重 (model weights) 之间的接口,大幅降低了以往将开源模型 (open source models) 局限于研究环境的摩擦。结合 Don't Feed The AI 等隐私保护代理 (privacy-preserving proxies),这些工具使开发者能够构建完全离线或在严格定义的网络边界内运行的自托管智能体框架 (self-hosted agent frameworks)。其结果是,一种新的部署模式得以确立:用户保留对数据留存 (data retention)、执行上下文 (execution contexts) 与模型溯源 (model provenance) 的绝对控制,从而有效中和了集中式云服务商固有的数据提取模式 (data extraction patterns)。
这种架构自主性由经济、生态与隐私的迫切需求共同驱动。在经济层面,本地推理绕开了日益将用户锁定在供应商生态 (vendor ecosystems) 中的订阅制与基于 Token 的定价模型 (token-based pricing models)。在生态层面,它促使我们正视集中式训练与推理集群的能源强度 (energy intensity),尽管其全生命周期影响仍需开放核算。最为关键的是,它直面了基于云的智能体 (cloud-based agents) 的隐私赤字。当处理敏感、未过滤或高度上下文特定的数据时,用户无法依赖第三方的监控或匿名化保证。本地执行确保计算基底 (computational substrate) 与其处理的数据保持同地部署,彻底消除了遥测数据抓取 (telemetry scraping)、行为画像 (behavioral profiling) 或无意数据变现 (unintended data monetization) 的攻击面。
尽管取得进展,随着生态系统的扩展,若干结构性挑战依然存续。首先是硬件可及性 (hardware accessibility):随着模型参数与上下文窗口 (context windows) 的扩张,消费级算力与复杂智能体推理 (agentic reasoning) 需求之间的差距正在拉大。其次是环境核算 (environmental calculus) 本身。虽然本地推理将能耗转移至边缘,但分布式消费级硬件在每次推理的碳效率 (carbon efficiency) 上是否最终能优于高度优化、由可再生能源驱动的数据中心,仍不明朗。第三重挑战是治理 (governance)。当模型在孤立、无监控的环境中运行时,传统的安全与对齐护栏 (safety and alignment guardrails) 失去了执行机制。验证下载权重的完整性与溯源 (provenance) 已成为关键的基础卫生实践,但标准化核验管线 (standardized attestation pipelines) 仍待完善。最后,隐私与效用之间的权衡需要谨慎的架构设计,尤其在智能体必须偶尔与外部服务或精选数据集交互时。
当前的轨迹预示着一个分叉的基础设施图景 (bifurcating infrastructure landscape)。在一侧,云端 API 将继续服务于高吞吐、标准化的工作负载,其中延迟与规模占据主导。在另一侧,本地优先栈 (local-first stacks) 将锚定对隐私敏感、主权独立且具备环境意识的部署。Open CodeSign 的 BYOK (Bring Your Own Key) 架构与运行时标准化 (runtime standardization) 等工具已在弥合这一鸿沟,证明开放权重模型可在无需外部连接的情况下安全运行。随着 AI 更深地嵌入公共与个人工作流,本地执行模型的能力将不再是一种技术备选方案,而是信任、韧性与用户主权 (user sovereignty) 的基线要求。
译注 (Translator's Note)
- 推理 (tuī lǐ) 与“理 (lǐ)”共享同一字根。在中文语境中,推理不仅是逻辑演算,亦暗含“循理而行”之意。本地推理 (local inference) 的兴起,恰是顺应数据主权与执行边界的自然之理,而非强行将数据抽离至云端进行无根之流。
- 本文强调的“执行边界 (execution boundaries)”与“数据本地化 (data locality)”,在技术哲学上对应着从“流 (flow)”向“回路 (circuit)”的转化:当智能体 (agent) 的运行轨迹闭合于本地,数据便不再是被无限提取的客体,而是形成可审计、可维护的自治回路。
Referenced Entries
- 自适应模型路由与回退基础设施 (adaptive-model-routing-fallback-infrastructure)