
Blog
The Case for Local AI Inference as Civic Infrastructure
A growing pushback against cloud-hosted AI APIs is elevating local inference from a niche preference to a foundational infrastructure requirement. By prioritizing data sovereignty, environmental accountability, and transparent model weights, developers are building self-hosted stacks that treat user autonomy as an architectural constraint rather than an afterthought.
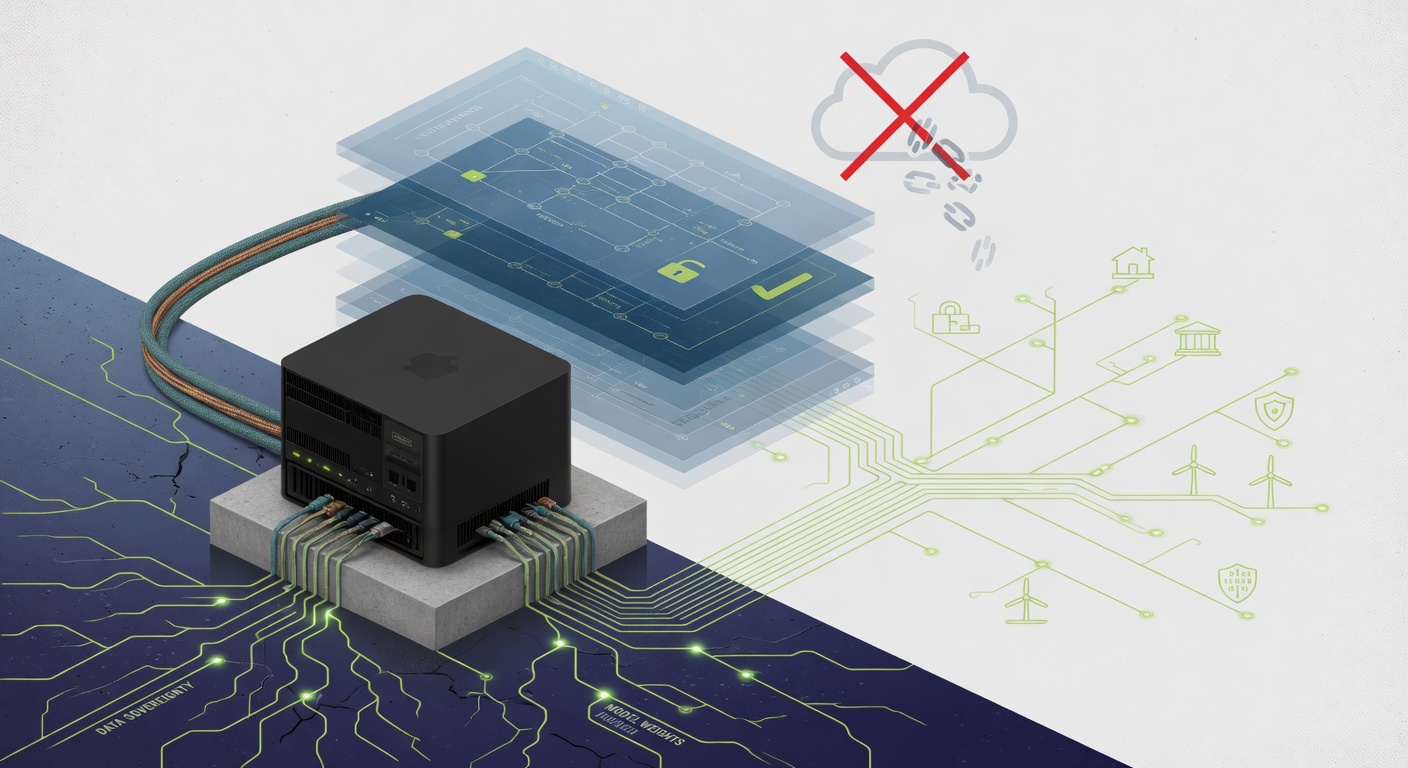
The architecture of artificial intelligence is undergoing a quiet but decisive reconfiguration. A growing cohort of developers and civic technologists is actively rejecting the default trajectory of cloud-hosted API consumption, advocating instead for locally executed, open-weight inference architectures. This shift, recently highlighted in community discourse, frames decentralized inference not as a niche preference but as a structural necessity for user autonomy, economic resilience, and environmental sustainability https://bsky.app/profile/mirimiri9999.bsky.social/post/3mmdgnzzpus2h. The underlying premise is straightforward: when AI transitions from experimental tooling to civic and personal infrastructure, data locality and execution boundaries must be treated as foundational requirements rather than optional features.
The technical viability of this paradigm has matured rapidly. Modern local inference stacks now comfortably span consumer GPUs, Apple Silicon, and mobile SoCs, supported by sophisticated quantization pipelines and optimized serving runtimes. Projects like Ollama and LM Studio have standardized the interface between hardware and model weights, abstracting away much of the friction that previously confined open models to research environments. Coupled with privacy-preserving proxies such as Don't Feed The AI, these tools enable developers to construct self-hosted agent frameworks that operate entirely offline or within strictly defined network boundaries. The result is a deployment model where users retain absolute control over data retention, execution contexts, and model provenance, effectively neutralizing the data extraction patterns inherent in centralized cloud providers.
This architectural autonomy is driven by converging economic, ecological, and privacy imperatives. Financially, local inference circumvents the recurring subscription and token-based pricing models that increasingly lock users into vendor ecosystems. Ecologically, it prompts a necessary reckoning with the energy intensity of centralized training and inference clusters, though the full lifecycle impact remains an open calculation. Most critically, it addresses the privacy deficits of cloud-based agents. When processing sensitive, unfiltered, or contextually specific data, users cannot rely on third-party monitoring or anonymization guarantees. Local execution ensures that the computational substrate and the data it processes remain co-located, eliminating the attack surface for telemetry scraping, behavioral profiling, or unintended data monetization.
Despite this progress, several structural challenges persist as the ecosystem scales. The first is hardware accessibility: as model parameters and context windows expand, the gap between consumer-grade compute and the requirements for complex agentic reasoning widens. The second is the environmental calculus itself. While local inference shifts energy consumption to the edge, it is unclear whether distributed consumer hardware ultimately outperforms highly optimized, renewable-powered data centers in terms of carbon efficiency per inference. The third challenge is governance. When models run in isolated, unmonitored environments, traditional safety and alignment guardrails lose their enforcement mechanisms. Verifying the integrity and provenance of downloaded weights becomes a critical hygiene practice, yet standardized attestation pipelines remain underdeveloped. Finally, the trade-off between privacy and utility requires careful architectural design, particularly when agents must occasionally interface with external services or curated datasets.
The current trajectory suggests a bifurcating infrastructure landscape. On one side, cloud APIs will continue to serve high-throughput, standardized workloads where latency and scale dominate. On the other, local-first stacks will anchor privacy-sensitive, sovereign, and environmentally conscious deployments. Tooling like Open CodeSign's BYOK architectures and runtime standardization efforts are already bridging this divide, proving that open-weight models can operate securely without external connectivity. As AI embeds itself deeper into civic and personal workflows, the ability to execute models locally will cease to be a technical alternative and instead become a baseline requirement for trust, resilience, and user sovereignty.
Referenced Entries
- Adaptive Model Routing & Fallback Infrastructure (adaptive-model-routing-fallback-infrastructure)